- Explanation & Reference
- Explore
- Operations
- Data Enrichment
- Data Generation
-
Data Generation
In this tab, you can generate new datasets and choose distribution types. You can create multiple distributions simultaneously by collecting them in the command box.
Note
This tutorial assumes that you already selected a project and imported data. For more information please visit on
Project and Import Data section.
User Interface Structure
This is a detailed description of all settings you can define for this operation.
Main Settings
Type a positive integer greater than 0 as size for the dataset.
Distribution Options
Select the distribution you want to create. Depending on the distribution, you need to provide one or up to four parameters; see details in the table Distributions and parameters. You can also create a preview of your distribution settings with the Show button.
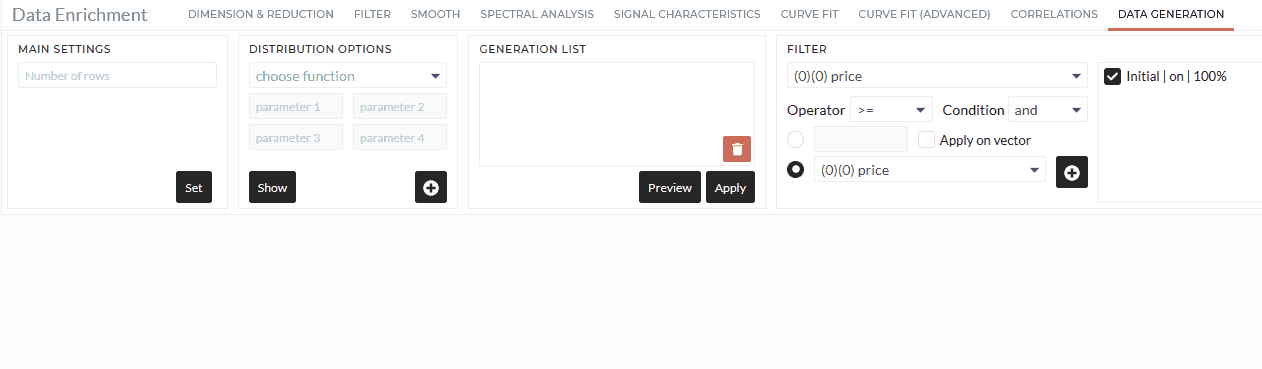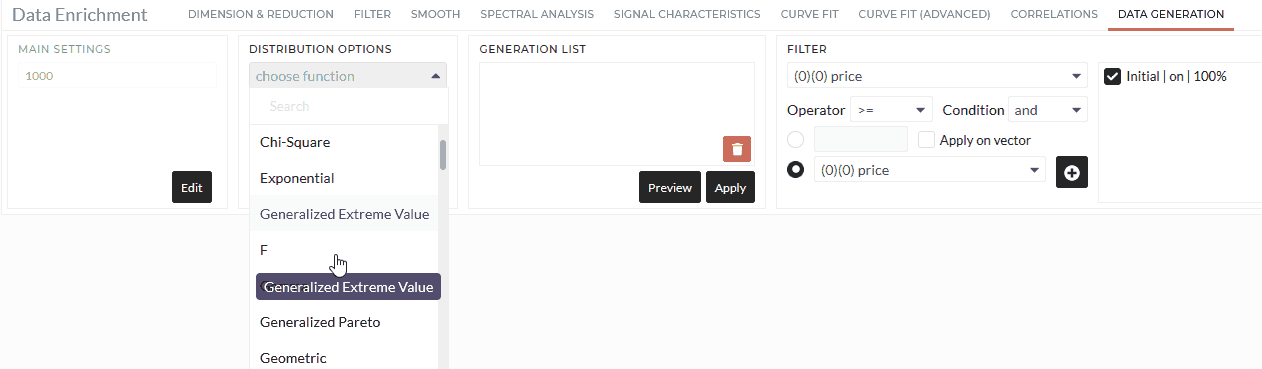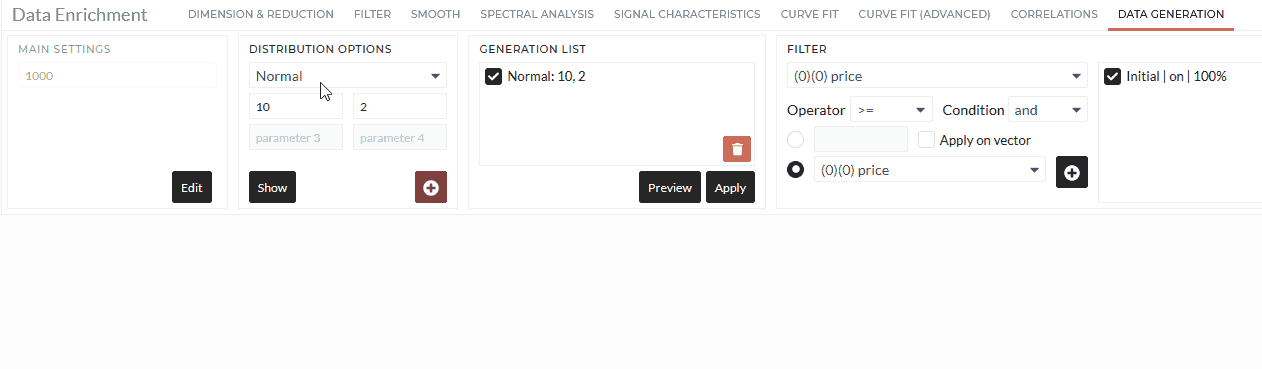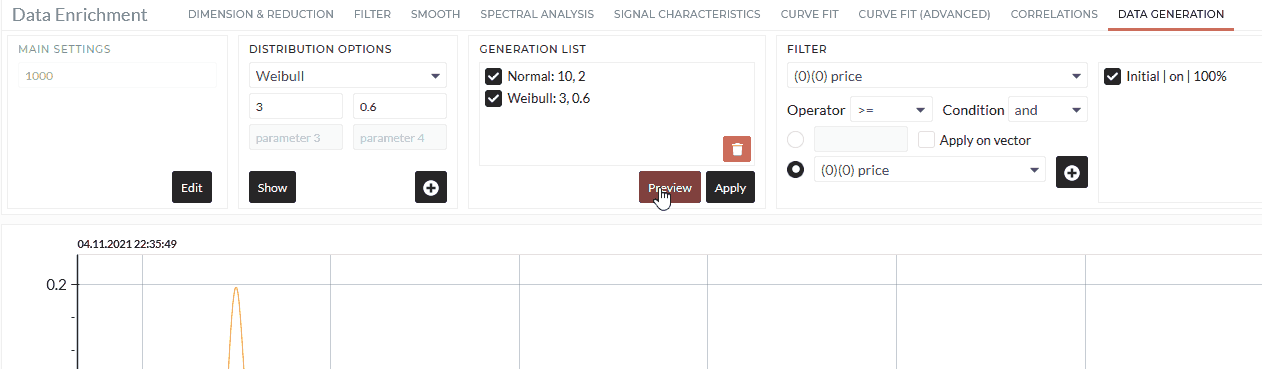
Generation List
Collect all distributions you want to generate in this box.
Filter
As in all Data Enrichment Tabs, you can select only a part of the data by using a Filter.
A more detailed description of Filters can be found here
Since you are generating new data, the filter will have no effect.
Preview/Apply
Preview button will do the operation but will not save the data, while Apply will give you the option to save the data in a folder in content. More information is available in here
Basic Usage
Creating new datasets is easy and follows the same rules:
- First, you type the data size (number of rows) in the main settings. It has to be a positive integer greater than 0.
- Select the distribution type you want.
- Type the distribution parameters; see Distributions and parameters for more details.
- Add it into the command collection box.
- Apply the Operation.
The following animation shows an example usage, where you create a Normal and Weibull distribution with 1000 rows simultaneously.
Distributions and parameters
| Distribution |
Parameter 1 |
Parameter 2 |
Parameter 3 |
Parameter 4 |
Link |
| Beta |
alpha (>0) |
beta (>0) |
- |
- |
Link |
| Binomial |
n (>0) |
p (0<=p<=1) |
- |
- |
Link |
| Birnbaum Saunders |
c (>0) |
- |
- |
- |
Link |
| Burr Type XII |
c (>0) |
d (>0) |
- |
- |
Link |
| Chi-Square |
df (>0) |
- |
- |
- |
Link |
| Exponential |
scale |
- |
- |
- |
Link |
| Generalized Extreme Value |
mu |
beta (>=0) |
- |
- |
Link |
| F |
df numerator (>0) |
df denumerator (>0) |
- |
- |
Link |
| Gamma |
shape (>=0) |
scale (>=0) |
- |
- |
Link |
| Generalized Pareto |
shape |
scale (>=0) |
loc |
- |
Link |
| Geometric |
p (0<=p<=1) |
- |
- |
- |
Link |
| Half-Normal |
loc |
scale (>0) |
- |
- |
Link |
| Hypergeometric |
number of good (0<=ngood<=1e9) |
number of bad (0<=nbad<=1e9) |
- |
- |
Link |
| Inverse Gaussian |
mean (>0) |
scale (>0) |
- |
- |
Link |
| Logistic |
loc |
scale (>0) |
- |
- |
Link |
| Loglogistic |
shape (>0) |
loc |
scale (>=0) |
- |
Link |
| Lognormal |
mean |
standard deviation (>=0) |
- |
- |
Link |
| Nakagami |
nu (>0) |
scale (>=0) |
- |
- |
Link |
| Negative Binomial |
n (>0) |
p (0<=p<=1) |
- |
- |
Link |
| Noncentral F |
df numerator (>0) |
df denumerator (>0) |
nonc (>=0) |
- |
Link |
| Noncentral t |
df (>0) |
nc |
- |
- |
Link |
| Noncentral Chi-Squared |
df (>0) |
nonc (>0) |
- |
- |
Link |
| Normal |
mean |
standard deviation (>=0) |
- |
- |
Link |
| Poisson |
lambda (>=0) |
- |
- |
- |
Link |
| Rayleigh |
scale (>=0) |
- |
- |
- |
Link |
| Rician |
shape (>0) |
loc |
scale |
- |
Link |
| Stable |
alpha (0< alpha<=2) |
beta (-1 <= beta <= 1) |
loc |
scale (>0) |
Link |
| Student's t |
df (>0) |
- |
- |
- |
Link |
| t Location-Scale |
df (>0) |
loc |
scale (>0) |
- |
Link |
| Uniform (Continuous) |
lower boundary |
upper boundary |
- |
- |
Link |
| Uniform (Discrete) |
lower boundary |
upper boundary |
- |
- |
Link |
| Weibull |
scale |
shape |
- |
- |
Link |
| Linspace |
start |
stop |
- |
- |
Link |
| Logspace |
start (>0) |
stop (>0) |
- |
- |
Link |
| Geomspace |
start (>0) |
stop (>0) |
- |
- |
Link |
| Arange |
start |
space |
- |
- |
Link |